The Large Directory
You are given a bucket with four directories in a very limited imitation of Amazon S3. Your task is to find the directory that has more files than any of the other three by issuing a given CLI command only once.
The structure of the directories is illustrated by the following diagram.
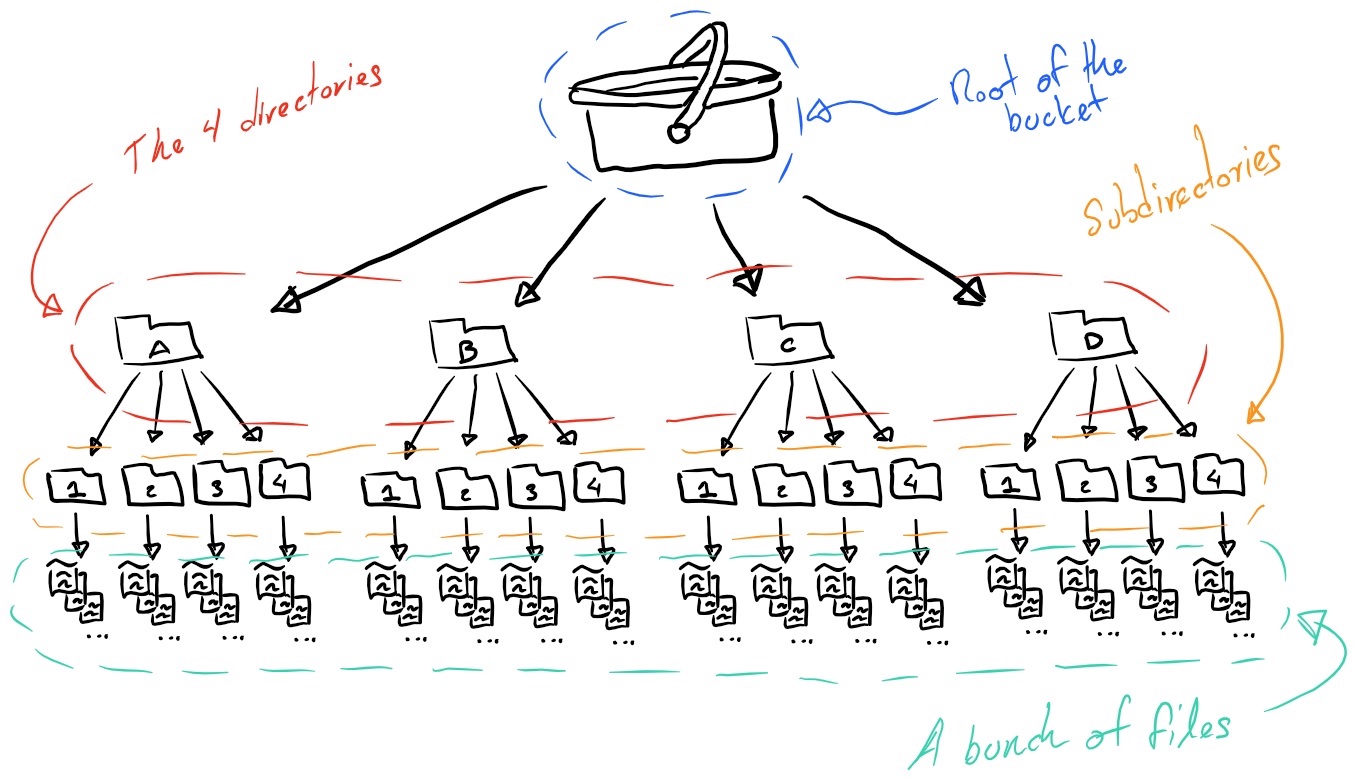
Three of the four directories contain four subdirectories and each of those subdirectories contains 1000 files. The remaining directory contains four subdirectories and each of those subdirectories contains 1001 files.
You may only use CLI command count. The Syntax of the command is
count <file list>. An element of the file list may be a file, a
directory or a pattern. A pattern may consist of any glob pattern,
regular expression, and brace expansion that Bash accepts (reference
here). The command
returns the file count that corresponds to the file list. For
example, when the subdirectories of directory A contain 1000 files
each, the output of command count /A/1 /A/2 is 2000. The following
command uses brace expansion and gives the same output: count
/A/{1,2}.
Solution
Click here to see solution.
We compose the following command that returns a different file count for each possible case.count /B/1 /C/1 /C/2 /D/1 /D/2 /D/3 Directory that has more files | File count
----------------------------------------------
A | 6000
B | 6001
C | 6002
D | 6003