The Stock Profit Problem
The Stock Profit Problem is an interview question you can find in the wild. The problem asks for the biggest profit given a sequence of stock prices. As usual, there is a naive solution that won’t cut it. I explain an efficient solution in 6 different programming languages and give you a hint for further study.
By the way, the drama in the problem statement and the solution is fictional, created by me, totally uncalled for, and any resemblance to a real life situation is purely coincidental.
Problem
You are a developer for a company that sells a program that analyses stock. One day, your manager asks you to develop a feature that tells the user the biggest profit for a given stock over a period of time in the past. For example, the following is the price of stock FAKE over the last 7 days.
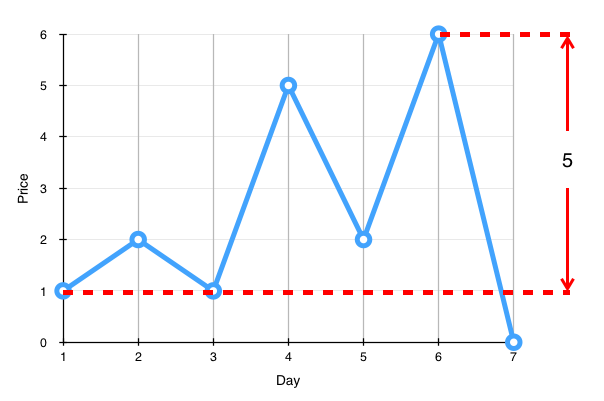
The biggest profit is 5 USD, so that’s what the feature will tell the user. There are two possible ways to obtain the biggest profit. One way is buy on day 1 and sell on day 6. The other is buy on day 3 and sell on day 6. You only have to report the profit.
For a moment you have the slight impression the biggest profit is 6 USD, because the difference in price between day 6 and day 7 is 6 USD. However, you realize that that makes absolutely no sense because buying on day 6 and selling on day 7 does not give you a profit, it gives you a loss, the biggest loss.
Given the example, you are pretty sure that you understand what your manager is asking for. You figure that the most difficult part of the feature is the algorithm that computes the biggest profit and that the rest of the changes are just run-of-the-mill scaffolding and unit tests.
So you have a go at the algorithm.
You determine that the input to the algorithm is a sequence of prices over a period of time.
For example, the input A that corresponds to the price of stock FAKE over the last 7 days is the following.
A: 1 2 1 5 2 6 0
day: 1 2 3 4 5 6 7
len: 7You also determine that given the array of prices, the biggest profit is $@max \{ A[j] - A[i] \,|\, 1 \leq i < j \leq 7 \}@$. So you translate that mathematical statement for the biggest profit into the following algorithm.
S(A, len)
1: max := A[1] IF len > 0
2: FOR i := 1 TO len
3: FOR j := i + 1 TO len
4: IF A[j] - A[i] > max
5: max := A[j] - A[i]
6: RETURN maxYou convince yourself that algorithm S works because line 4 considers each element of $@\{ A[j] - A[i] \,|\, 1 \leq i < j \leq 7 \}@$ and selects the maximum so far.
Boom! Solved, right?
Wrong.
But you only find that your solution is wrong one hour before the deadline for the feature, when a QA analyst tells you that your feature is timing out some acceptance tests.
The problem is that algorithm S is too slow.
The reason is that the running time of algorithm $@S@$ is quadratic.
Already with 100,000 data points, the algorithm takes more than 1 second to give you the corresponding answer.
Given that input sequences usually consists of hundreds of thousands of prices, this is totally unacceptable because end users won’t buy software that takes more than half a second to react.
I mean, would you?
After a well deserved moment of sheer panic and seriously considering how much work would it be to update your CV, you get a grip of yourself.
(Psst, this is where you try to come up with an algorithm that takes half a second for an input of length 1,000,000 in a fast language like C. Use this benchmark. The biggest profit is 32767. Your program should read the input from stdin and print the biggest profit. No peeking at the solution. Scroll down only when you have a solution or you are sure you want to give up.)
Are you done?
Very good.
Solution
Here is an algorithm that solves the problem in linear time.
F(A, len)
1: min := A[1] IF len > 0
2: max := 0
3: FOR i := 2 TO len
4: IF A[i] - min > max
5: max := A[i] - min
6: IF A[i] < min
7: min := A[i]
8: RETURN maxBoom!
Don’t spend too much time looking at it.
Instead, read the following explanation of algorithm F.
By the way, if you had read Jill Rides Again, you could have solved this problem faster because the approach of algorithm F is similar to the approach in Jill Rides Again.
The approach of algorithm F consists in refining a candidate solution to input sequence A by solving each prefix of A, from left to right.
For example, consider input sequence A = [1, 2, 1, 5, 2, 6, 0].
The solution for each prefix of A is the following.
Prefix sequence : Solution for prefix / Current candidate solution for A
1 : 0
1, 2 : 1
1, 2, 1 : 1
1, 2, 1, 5 : 4
1, 2, 1, 5, 2 : 4
1, 2, 1, 5, 2, 6 : 5
1, 2, 1, 5, 2, 6, 0: 5The initial candidate solution is 0 and corresponds to the prefix of length 0 (a.k.a. the empty prefix). Line 2 sets the initial candidate solution.
The solution to prefix sequence 1 is 0.
The reason is that any prefix of one element does not give you a profit.
Given that A has more than one element, algorithm F keeps the initial candidate solution as the solution to prefix 1.
The algorithm does that by skipping the first element of the input sequence (FOR i := 2 ...) in line 3.
The solution to prefix sequence 1, 2 is 1.
The reason is that there is no other way to make a profit than to buy at the first price and sell at the second price.
Algorithm F determines that 1 is the solution to 1, 2 by choosing the maximum value between the solution to prefix 1 and the profit given by selling at the second price.
The algorithm does that in lines 4 and 5.
The solution to prefix sequence 1, 2, 1 is 1.
The reason is that appending 1 to prefix 1, 2 does not give you a bigger profit.
Algorithm F determines that 1 is the solution to 1, 2, 1 by choosing the maximum value between the solution to prefix 1, 2 (that is 1) and 0.
Alternative 0 is the maximum profit that is possible when you sell at the last price.
The profit is given by the difference of the last price (that is 1) and the minimum price amongst the previous prices (that is also 1).
Lines 6 and 7 do the bookkeeping of the minimum price (min).
The profit is computed in line 4 (... A[i] - min ...).
For each of the subsequent prefixes, the solution is either the solution to the previous prefix or the maximum profit obtained by selling at the last price, whatever is biggest.
One more thing.
Bonus points if you can tell me why the following algorithm does the same that algorithm F does.
G(A, len)
1: min := A[1] IF len > 0
2: max := 0
3: FOR i := 2 TO len
4: IF A[i] < min
5: min := A[i]
6: ELSE IF A[i] - min > max
7: max := A[i] - min
8: RETURN maxImplementation
Are you still reading? Nice. Let me make it worth your while.
Here is algorithm G implemented in 6 different languages.
Enjoy and don’t forget to subscribe!
C
Get a Makefile for the following program here.
#include <stdio.h>
#define MAX_LEN 1000000
#define Si(i) scanf("%d", &i)
int alg_g(int *A, int len) {
int min = len > 0 ? A[0] : 0;
int max = 0;
for(int i = 0; i < len; i++)
if(A[i] < min)
min = A[i];
else if(A[i] - min > max)
max = A[i] - min;
return max;
}
int main() {
int A[MAX_LEN];
int len = 0;
int n;
while(Si(n) != EOF)
A[len++] = n;
printf("%d\n", alg_g(A, len));
return 0;
}Golang
Get a Makefile for the following program here.
package main
import "fmt"
const MAX_LEN = 1000000
func algG(A []int) int {
if len(A) == 0 {
return 0
}
min := A[0]
max := 0
for i := 0; i < len(A); i++ {
if A[i] < min {
min = A[i]
} else if A[i] - min > max {
max = A[i] - min
}
}
return max
}
func main() {
A := make([]int, 0, MAX_LEN)
var n int
_, err := fmt.Scanf("%d", &n)
for err == nil {
A = append(A, n)
_, err = fmt.Scanf("%d", &n)
}
fmt.Println(algG(A))
}Java
Get a Makefile for the following program here.
import java.util.Scanner;
public class main {
private static int MAX_LEN = 1000000;
private static int algG(int[] A) {
int min = A.length > 0 ? A[0] : 0;
int max = 0;
for(int i = 0; i < A.length; i++)
if(A[i] < min)
min = A[i];
else if(A[i] - min > max)
max = A[i] - min;
return max;
}
public static void main(String[] args) {
int[] A = new int[MAX_LEN];
int len = 0;
int n;
Scanner in = new Scanner(System.in);
while(in.hasNextInt())
A[len++] = in.nextInt();
System.out.println(algG(A));
}
}Ruby
#!/usr/bin/env ruby
def alg_g(a)
min = (a && a[0]) || 0
max = 0
a.each do |a_i|
if a_i < min
min = a_i
elsif a_i - min > max
max = a_i - min
end
end
return max
end
puts alg_g STDIN.read.split("\n").map { |a_i| a_i.to_i }OCaml
You may compile the following program. Get a Makefile for the following program here.
#!/usr/bin/env ocaml
open Printf;;
let alg_g a =
let rec do_et profit max = function
| [] -> profit
| a_i :: a ->
if a_i > max then
do_et profit a_i a
else if max - a_i > profit then
do_et (max - a_i) max a
else
do_et profit max a
in
match a with
| [] -> 0
| a_last :: a' -> do_et 0 a_last a'
let rec read_input acc =
let l =
try Some (int_of_string (read_line ()))
with _ -> None
in
match l with
| None -> acc
| Some i ->
read_input (i :: acc)
let main () =
let a = read_input [] in
printf "%d\n" (alg_g a)
let _ = main ()This implementation considers prices from right to left. Did you notice that?
Prolog
You may run/compile the following program with SWI Prolog. Get a Makefile for the following program here.
#!/usr/bin/env swipl
alg_g([], 0).
alg_g([A_LAST|Ap], P) :-
do_et(0, A_LAST, Ap, P).
do_et(P, _, [], P).
do_et(Pp, M, [Ai|A], P) :-
Ai @> M ->
do_et(Pp, Ai, A, P) ;
(Ppp is M - Ai, Ppp @> Pp) ->
do_et(Ppp, Ai, A, P) ;
do_et(Pp, M, A, P).
read_input(A) :- read_input([], A).
read_input(Acc, A) :-
read_line_to_codes(user_input, L),
L \== end_of_file,
number_codes(N, L),
read_input([N|Acc], A).
read_input(A, A).
main :-
prompt(_, ''),
read_input(A),
alg_g(A, P),
print(P),
nl,
halt.
:- main.This implementation considers prices from right to left. Did you notice that?